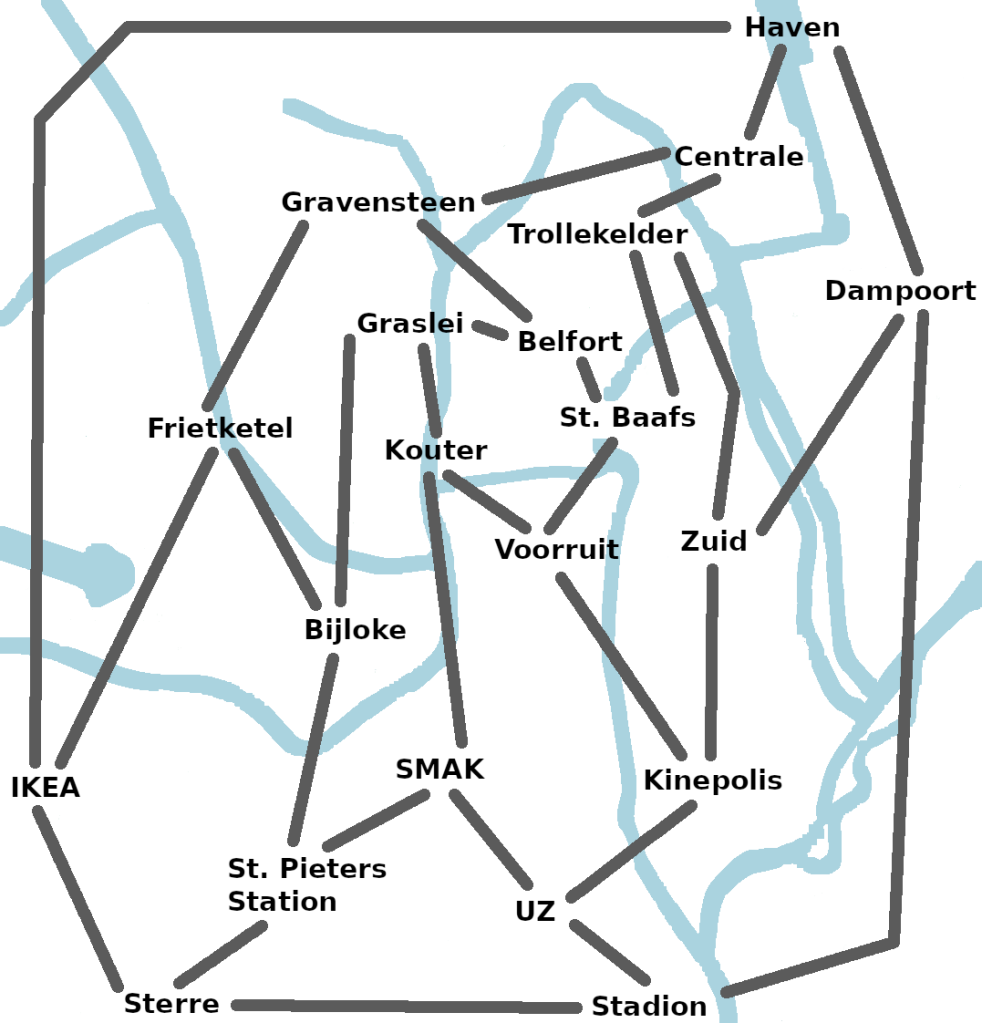
Last year Zhirayr Avetisyan and I created a math riddle about the games cops and robbers. It was part of an outreach event to high-school student at Ghent University. You can find it in this post here. The story was that a group of mathematicians wants to walk around the city of Ghent and have fun, while a group of bureaucrats wants to destroy that fun.
1. The New Version for SUSTech
This year I was asked to make a riddle for Pi Day at my new university, the Southern University of Science and Technology (SUSTech) in Shenzhen, China. Now I was asked very short notice, so I simply wanted to re-use last year’s riddle. There were two problems: (1) I can hardly use a city map of Ghent for a riddle at a university in Shenzhen. (2) In Belgium or Germany most civil servants and bureaucrats do not mind when people make fun of them. Indeed, I probably know all my civil servant jokes from civil servants (E.g.: Two civil servants meet in the hallway. One speak: “Oh! You cannot sleep either?”). Even though China is probably the most bureaucratic country which I have ever lived in (and I have lived in Germany, obviously), this is serious business and the story had to be replaced. The responsible secretary come up with a very cute story: A robot escaped from the robotics lab and students have to catch it again.
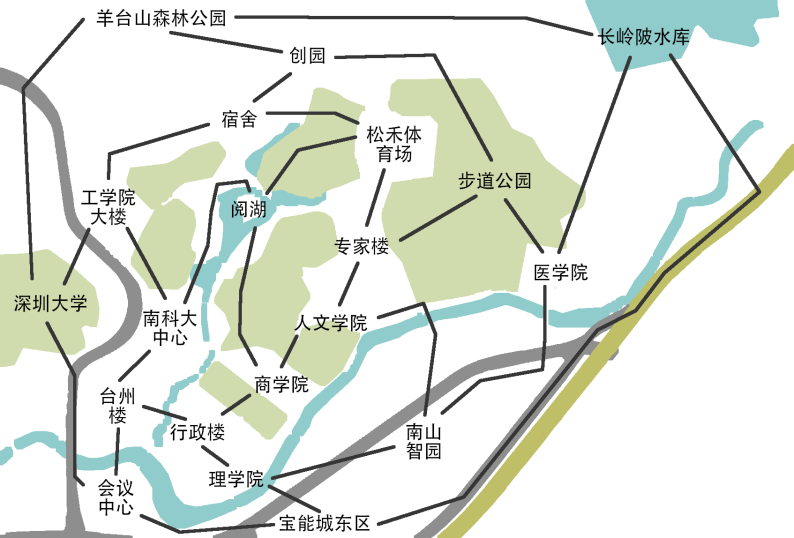
Here is the map of SUSTech’s campus:
 functions (or Cameron-Liebler classes) of
functions (or Cameron-Liebler classes) of  -spaces in an
-spaces in an  -dimensional vector space
-dimensional vector space over the field with
over the field with  elements for
elements for 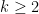 fixed).
fixed). ) goes back to a
) goes back to a